AI projects aren’t just “software with data.” Here’s how AI development differs from traditional engineering—and why knowing the distinction can help you deliver more successful products.
When you hear “development,” you might think of writing code, building features, and launching software. But when it comes to AI, that workflow changes dramatically. AI development (including ML and data science) requires a radically different mindset—one focused on iterative learning, data cleanup, model refinement, and ongoing monitoring.
🔄 1. Development Lifecycles: Iteration vs Linearity
Traditional software follows a linear SDLC: design → build → test → deploy → maintain. Each step leads seamlessly to the next.
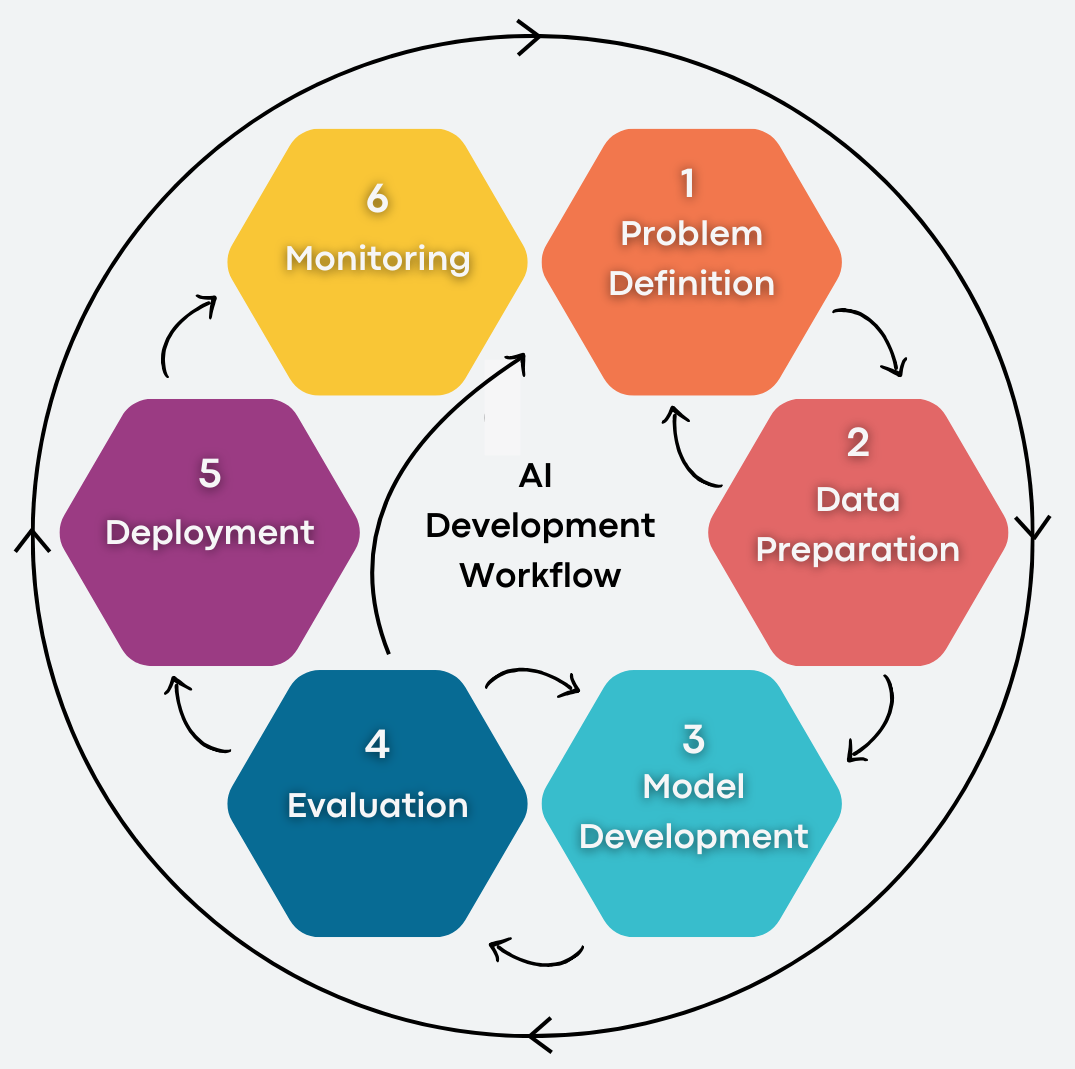
AI development is inherently cyclical:
- Define the problem—e.g., “Reduce cart abandonment by 15%.”
- Prepare data—clean, organize, and explore datasets.
- Experiment with models—try neural nets, decision trees, SVMs, etc.
- Evaluate—use test sets, tune hyperparameters.
- Deploy—serve model as API.
- Monitor & retrain—check for model drift and update regularly.
This loop—often referred to as CRISP-DM plus monitoring—is essential because AI systems must adapt to changing data and conditions.
🎯 2. Success Metrics: Accuracy vs Requirements
In regular software, success is defined by meeting requirements: does the app function as expected? AI performance, by contrast, is measured in terms like accuracy, precision/recall, and generalization. You rarely “finish” an AI model—it’s continually validated, retrained, and scored against new data.
🧰 3. Tools & Skills: Data Science vs Engineering
AI development requires:
- Data cleaning and feature engineering
- Proficiency with ML libraries (TensorFlow, PyTorch, scikit-learn)
- Understanding metrics, overfitting, and bias
- Deployment considerations for model latency and monitoring
Software engineering focuses on:
- Designing APIs, UI/UX, system architecture
- Writing and testing robust code in languages like JavaScript, Java, or PHP
- Ensuring maintainability, scaling, and dev workflows
Roles may overlap—often data scientists integrate models, and engineers assist with scaling—but both skill sets are essential.
🚨 4. Risk Management & Monitoring
In software projects, testing focuses on correctness and stability. In AI, the real risk is model drift—model performance can degrade as data changes. That’s why monitoring, automated alerts, and retraining pipelines are critical parts of AI systems.
💡 5. Team Collaboration: Data-Informed vs Requirement-Driven
Standard software projects rely on upfront requirements from stakeholders. AI projects, however, often start vaguely and become clearer as the team explores the data. This demands ongoing collaboration between domain experts, data scientists, and engineers.
🛠 Putting It All into Practice
- Start simple: gather data, explore trends, prototype a baseline model.
- Design for evolution: build CI/CD pipelines that include retraining and validation.
- Instrument everything: track prediction accuracy, latency, biases.
- Collaborate continuously: align your model development to clear business KPIs.
🔮 Final Thoughts
AI development doesn’t just add a machine learning layer to your existing process—it requires a shift in mindset. Success is measured in performance metrics, iteration, and model maintenance—not static specs. Projects succeed when teams embrace experimentation, monitor continuously, and build ML-native workflows.
At Web Expert Solution, we help teams bridge the gap between ML innovation and robust software engineering. Follow us for deep dives on AI architecture, data engineering tips, and model deployment strategies—all in an engineer-friendly format.